Принципы работы с большими данными, парадигма MapReduce / Блог компании DCA (Data-Centric Alliance) / Хабр
Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и освятить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
| |
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
<user_id>,<country>,<city>,<campaign_id>,<creative_id>,<payment></p>
11111,RU,Moscow,2,4,0.3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Решение:
|
|
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.
Youtube-Канал автора об анализе данных
Ссылки на другие части цикла:
Часть 2: Hadoop
Часть 3: Приемы и стратегии разработки MapReduce-приложений
Часть 4: Hbase
Что такое Big Data простыми словами? Применение больших данных
Через 10 лет мир перейдет в новую эпоху — эпоху больших данных. Вместо виджета погоды на экране смартфона, он сам подскажет вам, что лучше одеть. За завтраком телефон покажет дорогу, по которой вы быстрее доберетесь до работы и когда нужно будет выехать.
Под влиянием Big Data изменится все, чего бы не коснулся человек. Разберемся, что это такое, а также рассмотрим реальное применение и перспективы технологии.
Навигация по материалу:
Что такое Big data?
Большие данные — технология обработки информации, которая превосходит сотни терабайт и со временем растет в геометрической прогрессии.
Такие данные настолько велики и сложны, что ни один из традиционных инструментов управления данными не может их хранить или эффективно обрабатывать. Проанализировать этот объем человек не способен. Для этого разработаны специальные алгоритмы, которые после анализа больших данных дают человеку понятные результаты.
В Big Data входят петабайты (1024 терабайта) или эксабайты (1024 петабайта) информации, из которых состоят миллиарды или триллионы записей миллионов людей и все из разных источников (Интернет, продажи, контакт-центр, социальные сети, мобильные устройства). Как правило, информация слабо структурирована и часто неполная и недоступная.
Как работает технология Big-Data?

Пользователи социальной сети Facebook загружают фото, видео и выполняют действия каждый день на сотни терабайт. Сколько бы человек не участвовало в разработке, они не справятся с постоянным потоком информации. Чтобы дальше развивать сервис и делать сайты комфортнее — внедрять умные рекомендации контента, показывать актуальную для пользователя рекламу, сотни тысяч терабайт пропускают через алгоритм и получают структурированную и понятную информацию.
Сравнивая огромный объем информации, в нем находят взаимосвязи. Эти взаимосвязи с определенной вероятностью могут предсказать будущее. Находить и анализировать человеку помогает искусственный интеллект.
Нейросеть сканирует тысячи фотографий, видео, комментариев — те самые сотни терабайт больших данных и выдает результат: сколько довольных покупателей уходит из магазина, будет ли в ближайшие часы пробка на дороге, какие обсуждения популярны в социальной сети и многое другое.
Методы работы с большими данными:
- Машинное обучение
- Анализ настроений
- Анализ социальной сети
- Ассоциация правил обучения
- Анализ дерева классификации
- Генетические алгоритмы
- Регрессионный анализ
Машинное обучение
Вы просматриваете ленту новостей, лайкаете посты в Instagram, а алгоритм изучает ваш контент и рекомендует похожий. Искусственный интеллект учится без явного программирования и сфокусирован на прогнозировании на основе известных свойств, извлеченных из наборов «обучающих данных».
Машинное обучение помогает:
- Различать спам и не спам в электронной почте
- Изучать пользовательские предпочтения и давать рекомендации
- Определять лучший контент для привлечения потенциальных клиентов
- Определять вероятность выигрыша дела и устанавливать юридические тарифы
Анализ настроений
Анализ настроений помогает:
- Улучшать обслуживание в гостиничной сети, анализируя комментарии гостей
- Настраивать стимулы и услуги для удовлетворения потребностей клиента
- Определить по мнениям в социальной сети о чем думают клиенты.
Анализ социальных сетей
Анализ социальных сетей впервые использовали в телекоммуникационной отрасли. Метод применяется социологами для анализа отношений между людьми во многих областях и коммерческой деятельности.
Этот анализ используют чтобы:
- Увидеть, как люди из разных групп населения формируют связи с посторонними лицами
- Выяснить важность и влияние конкретного человека в группе
- Найти минимальное количество прямых связей для соединения двух людей
- Понять социальную структуру клиентской базы
Изучение правил ассоциации
Люди, которые не покупают алкоголь, берут соки чаще, чем любители горячительных напитков?
Изучение правил ассоциации — метод обнаружения интересных взаимосвязей между переменными в больших базах данных. Впервые его использовали крупные сети супермаркетов для обнаружения интересных связей между продуктами, используя информацию из систем торговых точек супермаркетов (POS).
С помощью правил ассоциации:
- Размещают продукты в большей близости друг к другу, чтобы увеличились продажи
- Извлекают информацию о посетителях веб-сайтов из журналов веб-сервера
- Анализируют биологические данные
- Отслеживают системные журналы для обнаружения злоумышленников
- Определяют чаще ли покупатели чая берут газированные напитки
Анализ дерева классификации
Статистическая классификация определяет категории, к которым относится новое наблюдение.
Статистическая классификация используется для:
- Автоматического присвоения документов категориям
- Классификации организмов по группам
- Разработки профилей студентов, проходящих онлайн-курсы
Генетические алгоритмы
Генетические алгоритмы вдохновлены тем, как работает эволюция, то есть с помощью таких механизмов, как наследование, мутация и естественный отбор.
Генетические алгоритмы используют для:
- Составления расписания врачей для отделений неотложной помощи в больницах
- Расчет оптимальных материалов для разработки экономичных автомобилей
- Создания «искусственно творческого» контента, такого как игра слов и шутки
Регрессионный анализ
Как возраст человека влияет на тип автомобиля, который он покупает?
На базовом уровне регрессионный анализ включает в себя манипулирование некоторой независимой переменной (например, фоновой музыкой) чтобы увидеть, как она влияет на зависимую переменную (время, проведенное в магазине).
Регрессионный анализ используют для определения:
- Уровней удовлетворенности клиентов
- Как прогноз погоды за предыдущий день влияет на количество полученных звонков в службу поддержки
- Как район и размер домов влияют на цену жилья
Data Mining — как собирается и обрабатывается Биг Дата
Загрузка больших данных в традиционную реляционную базу для анализа занимает много времени и денег. По этой причине появились специальные подходы для сбора и анализа информации. Для получения и последующего извлечения информацию объединяют и помещают в “озеро данных”. Оттуда программы искусственного интеллекта, используя сложные алгоритмы, ищут повторяющиеся паттерны.
Хранение и обработка происходит следующими инструментами:
- Apache HADOOP — пакетно-ориентированная система обработки данных. Система хранит и отслеживает информацию на нескольких машинах и масштабируется до нескольких тысяч серверов.
- HPPC — платформа с открытым исходным кодом, разработанная LexisNexis Risk Solutions. HPPC известна как суперкомпьютер Data Analytics (DAS), поддерживающая обработку данных как в пакетном режиме, так и в режиме реального времени. Система использует суперкомпьютеры и кластеры из обычных компьютеров.
- Storm — обрабатывает информацию в реальном времени. Использует Eclipse Public License с открытым исходным кодом.
Реальное применение Big Data

Самый быстрый рост расходов на технологии больших данных происходит в банковской сфере, здравоохранении, страховании, ценных бумагах и инвестиционных услугах, а также в области телекоммуникаций. Три из этих отраслей относятся к финансовому сектору, который имеет множество полезных вариантов для анализа Big Data: обнаружение мошенничества, управление рисками и оптимизация обслуживания клиентов.
Банки и компании, выпускающие кредитные карты, используют большие данные, чтобы выявлять закономерности, которые указывают на преступную деятельность. Из-за чего некоторые аналитики считают, что большие данные могут принести пользу криптовалюте. Алгоритмы смогут выявить мошенничество и незаконную деятельность в крипто-индустрии.
Благодаря криптовалюте такой как Биткойн и Эфириум блокчейн может фактически поддерживать любой тип оцифрованной информации. Его можно использовать в области Big Data, особенно для повышения безопасности или качества информации.
Например, больница может использовать его для обеспечения безопасности, актуальности данных пациента и полного сохранения их качества. Размещая базы данных о здоровьи в блокчейн, больница обеспечивает всем своим сотрудникам доступ к единому, неизменяемому источнику информации.
Также, как люди связывают криптовалюту с волатильностью, они часто связывают большие данные со способностью просеивать большие объемы информации. Big Data поможет отслеживать тенденции. На цену влияет множество факторов и алгоритмы больших данных учтут это, а затем предоставят решение.
Перспективы использования Биг Дата
Blockchain и Big Data — две развивающиеся и взаимодополняющие друг друга технологии. С 2016 блокчейн часто обсуждается в СМИ. Это криптографически безопасная технология распределенных баз данных для хранения и передачи информации. Защита частной и конфиденциальной информации — актуальная и будущая проблема больших данных, которую способен решить блокчейн.
Почти каждая отрасль начала инвестировать в аналитику Big Data, но некоторые инвестируют больше, чем другие. По информации IDC, больше тратят на банковские услуги, дискретное производство, процессное производство и профессиональные услуги. По исследованиям Wikibon, выручка от продаж программ и услуг на мировом рынке в 2018 году составила $42 млрд, а в 2027 году преодолеет отметку в $100 млрд.
По оценкам Neimeth, блокчейн составит до 20% общего рынка больших данных к 2030 году, принося до $100 млрд. годового дохода. Это превосходит прибыль PayPal, Visa и Mastercard вместе взятые.
Аналитика Big Data будет важна для отслеживания транзакций и позволит компаниям, использующим блокчейн, выявлять скрытые схемы и выяснять с кем они взаимодействуют в блокчейне.
Рынок Big data в России

Весь мир и в том числе Россия используют технологию Big Data в банковской сфере, услугах связи и розничной торговле. Эксперты считают, что в будущем технологию будут использовать транспортная отрасль, нефтегазовая и пищевая промышленность, а также энергетика.
Аналитики IDC признали Россию крупнейшим региональным рынком BDA. По расчетам в текущем году выручка приблизится к 1,4 миллиардам долларов и будет составлять 40% общего объема инвестиций в секторе больших данных и приложений бизнес-аналитики.
Где можно получить образование по Big Data (анализу больших данных)?
GeekUniversity совместно с Mail.ru Group открыли первый в России факультет Аналитики Big Data.
Для учебы достаточно школьных знаний. У вас будут все необходимые ресурсы и инструменты + целая программа по высшей математике. Не абстрактная, как в обычных вузах, а построенная на практике. Обучение познакомит вас с технологиями машинного обучения и нейронными сетями, научит решать настоящие бизнес-задачи.

После учебы вы сможете работать по специальностям:
Особенности изучения Big Data в GeekUniversity
Через полтора года практического обучения вы освоите современные технологии Data Science и приобретете компетенции, необходимые для работы в крупной IT-компании. Получите диплом о профессиональной переподготовке и сертификат.
Обучение проводится на основании государственной лицензии № 040485. По результатам успешного завершения обучения выдаем выпускникам диплом о профессиональной переподготовке и электронный сертификат на портале GeekBrains и Mail.ru Group.
Проектно-ориентированное обучение
Обучение происходит на практике, программы разрабатываются совместно со специалистами из компаний-лидеров рынка. Вы решите четыре проектные задачи по работе с данными и примените полученные навыки на практике. Полтора года обучения в GeekUniversity = полтора года реального опыта работы с большими данными для вашего резюме.
Наставник
В течение всего обучения у вас будет личный помощник-куратор. С ним вы сможете быстро разобраться со всеми проблемами, на которые в ином случае ушли бы недели. Работа с наставником удваивает скорость и качество обучения.
Основательная математическая подготовка
Профессионализм в Data Science — это на 50% умение строить математические модели и еще на 50% — работать с данными. GeekUniversity прокачает ваши знания в матанализе, которые обязательно проверят на собеседовании в любой серьезной компании.
GeekUniversity дает полтора года опыта работы для вашего резюме
В результате для вас откроется в 5 раз больше вакансий:

Для тех у кого нет опыта в программировании, предлагается начать с подготовительных курсов. Они позволят получить базовые знания для комфортного обучения по основной программе.
Поделитесь этим материалом в социальных сетях и оставьте свое мнение в комментариях ниже.

5
/
5
(
25
голосов
)
Самые последние новости криптовалютного рынка и майнинга:The following two tabs change content below.
Топ 30 инструментов Big Data (Биг Дата) для анализа данных. Как анализировать данные?
На сегодняшний день существуют тысячи Big Data — инструментов для анализа данных. Анализ данных — это процесс проверки, очистки, преобразования и моделирования данных с целью получения полезной информации, выводов и обоснований для принятия решений. Чтобы сэкономить ваше время, в этой статье перечислю 30 лучших Big Data — инструментов для анализа данных в области инструментов с открытым исходным кодом, инструментов визуализации данных, инструментов анализа настроений, инструментов извлечения данных и баз данных.

Open source инструменты для анализа данных
1. Knime
KNIME Analytics Platform — ведущий open source фреймворк для инноваций, зависящих от данных. Он поможет вам раскрыть скрытый потенциал ваших данных, найти новые свежие идеи, или предсказать будущие тенденции. KNIME Analytics Platform содержит в себе более 1000 модулей, сотни готовых к запуску примеров, широкий спектр интегрированных инструментов и широкий выбор современных доступных алгоритмов, определённо, это идеальный набор инструментов для любого специалиста в data science.
2. OpenRefine
OpenRefine (ранее Google Refine) — это мощный инструмент для работы с сырыми данными: их очистки, преобразования из одного формата в другой и расширения с помощью веб-сервисов и внешних данных. OpenRefine поможет вам с легкостью исследовать большие наборы данных.
3. R-Programming
Что если я скажу вам, что Project R это проект GNU, написанный на самом R? В первую очередь он написан на C и Fortran. И большинство его модулей написаны на самом R. Это открытая среда программирования для статистических вычислений и графики. Язык R широко используется среди майнеров данных для разработки статистического программного обеспечения и анализа данных. Простота его использования и расширяемость значительно повысили популярность R в последние годы. Помимо интеллектуального анализа данных, он предоставляет статистические и графические методы анализа, включая линейное и нелинейное моделирование, классические статистические тесты, анализ временных рядов, классификацию, кластеризацию и другое.
4. Orange
Orange это набор open source инструментов для анализа и визуализации результатов обработки данных, он прекрасно подходить как для экспертов, так и для новичков. Orange предоставляет большой набор инструментов для создания интерактивных рабочих процессов для анализа и визуализации данных. Orange предлагает пользователю различные способы визуализации — от точечных диаграмм, гистограмм, деревьев, до дендрограмм, сетей и тепловых карт.
5. RapidMiner
Как и KNIME, RapidMiner работает через визуальное программирование и способен обрабатывать, анализировать и моделировать данные. Благодаря открытому исходному коду платформы подготовки данных, машинного обучения и развертывания моделей RapidMiner дает командам, изучающим Data Science, больший простор для действий. Единая платформа для обработки данных ускоряет построение полных аналитических рабочих процессов — от подготовки данных и машинного обучения до проверки моделей и развертывания их в единой среде, что значительно повышает эффективность и сокращает время, затрачиваемое на проекты в сфере Data Science.
6. Pentaho
Pentaho уничтожает барьеры, которые мешают вашей компании получить всю выгоду от ваших данных. Платформа упрощает подготовку и трансформацию любых данных и включает в себя спектр инструментов для простого анализа, визуализации, исследования, составления отчетов и прогнозирования. Открытый, встраиваемый и расширяемый, Pentaho спроектирован так, чтобы любой член вашей команды — от разработчиков до бизнес-пользователей мог легко преобразовать данные в нечто стоящее.
7. Talend
Talend это ведущий поставщик программного обеспечения с открытым исходным кодом для компаний, управляющих данными. Наши клиенты подключаются в любом месте, при любой скорости соединения. От конкретного пользователя до облака, от пакетной до потоковой передачи и интеграции данных или интеграции приложений Talend подключается в масштабе больших данных, в 5 раз быстрее и за 20% от стоимости.
8. Weka
Weka, программное обеспечение с открытым исходным кодом, представляет собой набор алгоритмов машинного обучения для задач интеллектуального анализа данных. Алгоритмы могут быть применены непосредственно к набору данных или вызваны из вашего собственного Java-кода. Он также хорошо подходит для разработки новых схем машинного обучения, поскольку полностью реализован на языке программирования Java, а также поддерживает несколько стандартных задач интеллектуального анализа данных.
Для тех, кто некоторое время не программировал, Weka с ее графическим интерфейсом, обеспечивает самый простой переход в мир Data Science. Для пользователей с опытом программирования на Java есть возможность встраивать в библиотеку свой собственный код.
9. NodeXL
NodeXL — это программное обеспечение для анализа данных и визуализации, зависимостей и сетей. NodeXL предоставляет точные расчеты. Это бесплатное (но не профессиональное) программное обеспечение для анализа и визуализации сети с открытым исходным кодом. Это один из лучших статистических инструментов для анализа данных, который включает в себя расширенные сетевые метрики, доступ к импортерам данных в социальных сетях и автоматизацию.
10. Gephi
Gephi также представляет собой пакет программного обеспечения для сетевого анализа и визуализации с открытым исходным кодом, написанный на Java на платформе NetBeans. Подумайте об огромных картах дружбы, которые вы видите на LinkedIn или Facebook. Gephi развил это дальше, предоставляя точные расчеты.
Какие существуют программы для для визуализации собранных данных?
11. Datawrapper
Datawrapper — это интерактивный онлайн сервис для создания графиков и таблиц. После того, как вы загрузите данные из файла CSV, PDF или Excel или вставите их непосредственно в поле загрузки, Datawrapper генерирует гистограммы, графики, карты или любую другую связанную визуализацию. Графики Datawrapper можно встроить в любой веб-сайт или CMS с готовым для интеграции кодом. Многие журналисты и новостные организации используют Datawrapper для встраивания графиков в свои статьи. Он очень прост в использовании и создаёт эффективное и понятное визуальное представление информации.
12. Solver
Solver специализируется на предоставлении финансовой отчетности, составлении бюджета и анализа мирового уровня с помощью кнопки доступа ко всем источникам данных, которые обеспечивают рентабельность всей компании. Solver предоставляет инструмент BI360, который доступен как для облачного, так для и локального развертывания, с акцентом на четыре ключевых области аналитики.
13. Qlik
Qlik позволяет создавать визуализации, информационные панели и приложения, которые отвечают на самые важные вопросы вашей компании. Теперь вы можете увидеть всю историю, которая живет в ваших данных.
14. Tableau Public
Tableau демократизирует визуализацию с помощью элегантного, простого и интуитивно понятного инструмента. Он исключительно мощный в бизнесе, потому что он передает информацию через визуализацию данных. В процессе аналитики визуальные эффекты Tableau позволяют вам быстро исследовать гипотезу, верифицировать и просто исследовать данные, прежде чем отправиться в коварное статистическое путешествие.
15. Google Fusion Tables
Fusion Tables работает с Google Spreadsheets гораздо лучше и быстрее, чем его двоюродный брат . Google Fusion Tables — это невероятный инструмент для анализа данных, визуализации больших наборов данных и составления карт. Неудивительно, что невероятное картографическое программное обеспечение Google играет большую роль в продвижении этого инструмента в рейтинге ПО. Возьмите, к примеру, эту карту, которую я сделал, чтобы посмотреть на нефтедобывающие платформы в Мексиканском заливе
16. Infogram
Infogram предлагает более 35 интерактивных диаграмм и более 500 карт, которые помогут вам красиво визуализировать ваши данные. Создайте различные диаграммы, включая гистограммы, круговые диаграммы или облако слов. Добавьте карту к своей инфографике или отчету, чтобы произвести неизгладимое впечатление на вашу аудиторию.
Сентимент-инструменты
17. Opentext
Модуль OpenText Sentiment Analysis — это специализированный механизм классификации, используемый для идентификации и оценки субъективных моделей и выражений настроений в текстовом контенте. Анализ выполняется на уровне темы, предложения и документа и настроен на распознавание того, являются ли части текста фактическими или субъективными, если мнение, выраженное в этих частях контента, является положительным, отрицательным, смешанным или нейтральный.
18. Semantria
Semantria — это инструмент, который предлагает уникальный сервисный подход, собирая тексты, твиты и другие комментарии от клиентов и тщательно их анализируя, чтобы получить действенные и очень ценные идеи. Semantria предлагает анализ текста через API и плагин Excel. Он отличается от Lexalytics тем, что предлагается через API и плагин Excel, и включает в себя большую базу знаний и использует глубокое обучение.
19. Trackur
Автоматический анализ настроений Trackur анализирует конкретное ключевое слово, которое вы отслеживаете, а затем определяет, является ли мнение по этому ключевому слову положительным, отрицательным или нейтральным по отношению к документу. Это основная функция в алгоритме Trackur. Его можно использовать для мониторинга всех социальных сетей и основных новостей, чтобы получить представление руководителей о тенденциях, обнаружении ключевых слов, автоматическом анализе настроений.
20. SAS Sentiment Analysis
Анализ настроений SAS автоматически извлекает настроения в режиме реального времени или в течение определенного периода времени с помощью уникальной комбинации статистического моделирования и методов обработки естественного языка на основе правил. Встроенные отчеты показывают шаблоны и подробные реакции. Таким образом, вы можете отточить выраженные чувства.
С помощью текущих оценок вы уточните модели и скорректируете классификации, чтобы отразить возникающие темы и новые термины, относящиеся к вашим клиентам, компании или отрасли.
21. Opinion Crawl
Opinion Crawl — это онлайн-анализ настроений в отношении текущих событий, компаний, продуктов и людей. Opinion Crawl позволяет посетителям оценить настроение в сети по темам: человек, событие, компания или продукт. Выберите тему и вы получите оценку настроения для каждого конкретного случая. Для каждой темы вы получаете круговую диаграмму, показывающую текущее настроение в режиме реального времени, список заголовков последних новостей, несколько миниатюрных изображений и облако тегов ключевых семантических концепций, которые публика связывает с субъектом. Концепции позволяют вам увидеть, какие проблемы или события положительно влияют на настроение. Для более глубокой оценки веб-сканеры будут находить последние опубликованные материалы по многим популярным темам и текущим публичным вопросам и рассчитывать настроения для них на постоянной основе. Затем в постах блога будет показана тенденция настроений с течением времени, а также соотношение «положительный/отрицательный».
Какие существуют программы для парсинга данных в Интернете?
Отдельно отмечу наш сервис парсинга сайтов и мониторинга цен xmldatafeed.com. Мы на ежедневной основе парсим более 500 крупнейших сайтов России и наши клиенты могут использовать данные для аналитики и более точного ценообразования.

22. Octoparse
Octoparse — это бесплатный и мощный сканер веб-сайтов, используемый для извлечения практически всех видов данных с веб-сайта, которые Вас интересуют. Вы можете использовать Octoparse для копирования веб-сайта с его обширными функциями и возможностями. Его удобный интерфейс помогает людям без опыта программирования быстро привыкнуть к Octoparse. Он позволяет вам парсить весь текст с сайтов использующих AJAX, JavaScript, файлы cookie и, таким образом, вы можете загрузить практически весь контент веб-сайта и сохранить его в структурированном формате, таком как EXCEL, TXT, HTML или в ваши базы данных. Будучи усовершенствованным, он поддерживает запланированный облачный парсинг, позволяющий Вам извлекать динамические данные в режиме реального времени и вести лог-файл.
23. Content Grabber
Content Graber — это программное обеспечение для парсинга в Интернете, предназначенное для компаний. Он может извлекать контент практически с любого веб-сайта и сохранять его в виде структурированных данных в формате по вашему выбору, включая отчеты Excel, XML, CSV и большинство баз данных.
Он больше подходит для людей с продвинутыми навыками программирования, поскольку предлагает множество мощных сценариев редактирования, отладки интерфейсов для продвинутых пользователей. Пользователи могут использовать C # или VB.NET для отладки или написания сценариев по управлению процессом парсинга.
24. Import.io
Import.io — это платный веб-инструмент для парсинга данных, позволяющий извлекать информацию с веб-сайтов, что раньше было доступно только специалистам в области программирования. Просто выделите то, что вы хотите, и Import.io пройдёт по сайту и «изучит» то, что вас интересует. Import.io будет парсить, очищать и извлекать данные для анализа или экспорта.
25. Parsehub
Parsehub — это отличный веб-сканер, который поддерживает сбор данных с сайтов, использующих технологии AJAX, JavaScript, файлы cookie и т.д. Его технология машинного обучения позволяет считывать, анализировать а затем преобразовывать веб-документы в готовые данные. В бесплатной версии Parsehub вы можете настроить не более пяти публичных проектов. Платные планы подписки позволяют вам создать как минимум 20 частных проектов для парсинга веб-сайтов.
26.Mozenda
Mozenda — это облачный сервис парсинга. Он предоставляет множество полезных утилит для извлечения данных. Пользователи могут загружать извлеченные данные в облачное хранилище
Базы данных
27. Data.gov
Правительство США пообещало в прошлом году сделать все правительственные данные свободно доступными в интернете. Этот сайт является первым этапом и служит порталом для получения всевозможной удивительной информации обо всем — от климата до преступности.
28. US Census Bureau
Бюро переписи и статистики США — это обширная информация о жизни граждан США, охватывающая данные о населении, географические данные и информацию по образованию.
29. The CIA World Factbook
Общемировая книга фактов, выпускаемая ЦРУ, предоставляет информацию по истории, людям, правительству, экономике, географии, коммуникациям, транспорту, военным и транснациональным проблемам для 267 мировых юридических лиц.
30. PubMed
PubMed, разработанный Национальной медицинской библиотекой (NLM), предоставляет бесплатный доступ к MEDLINE, базе данных из более чем 11 миллионов библиографических ссылок и рефератов из почти 4500 журналов в области медицины, сестринского дела, стоматологии, ветеринарной медицины, фармации, системы здравоохранения и доклинической науки. PubMed также содержит ссылки на полнотекстовые версии статей на веб-сайтах партнерских издателей. Кроме того, PubMed обеспечивает доступ и ссылки на интегрированные базы данных молекулярной биологии, которые ведет Национальный центр биотехнологической информации (NCBI). Эти базы данных содержат последовательности ДНК и белка, данные о трехмерной структуре белка, наборы данных исследования населения и сборки полных геномов в интегрированной системе. Дополнительные библиографические базы данных NLM, такие как AIDSLINE, добавляются в PubMed. PubMed включает в себя «Old Medline». «Old Medline» охватывает промежуток 1950-1965 гг. (Обновляется ежедневно.)
с чего начать — Офтоп на vc.ru
Каждый обмен с социальными медиа, каждый цифровой процесс, каждое подключённое устройство генерирует большие данные, которые будут использоваться различными компаниями.
Сегодня компании используют Big Data для углубленного взаимодействия с клиентами, оптимизации операций, предотвращения угроз и мошенничества. За последние два года такие компании, как IBM, Google, Amazon, Uber, создали сотни рабочих мест для программистов и Data science.
Область больших данных слишком размылась на просторах интернета, и это может быть очень сложной задачей для тех, кто начинает изучать большие данные и связанные с ними технологии. Технологии данных многочисленны это может быть огромным препятствием для начинающих. Давайте попробуем разложить все по полочкам.
1. Как начать
В сфере Big Data существует много направлений. Но в широком смысле можно разделить на две категории:
- Big Data engineering.
- Big Data Analytics (Scientist).
Эти поля взаимозависимы, но отличаются друг от друга.
Big Data engineering занимается разработкой каркаса, сбора и хранения данных, а также делают соответствующие данные доступными для различных потребительских и внутренних приложений.
У вас хорошие навыки программирования и вы понимаете, как компьютеры взаимодействуют через интернет, но у вас нет интереса к математике и статистике. В этом случае вам больше подойдёт Big data engineering.
В то время как Big Data Analytics — среда использования больших объемов данных из готовых систем, разработанных Big data engineering. Анализ больших данных включает в себя анализ тенденций, закономерностей и разработку различных систем классификации и прогнозирования. После магических действий и танцев с бубном Data Analytics (Scientist) интерпретирует результаты.
Если вы хорошо разбираетесь в программировании, за чашкой кофе решаете сложные задачи по высшей математике, понимаете, что такое теория вероятностей, математический анализ, комбинаторики, тогда вам под
что это такое, где и как использовать технологии больших данных
Определение Big data обычно расшифровывают довольно просто – это огромный объем информации, часто бессистемной, которая хранится на каком либо цифровом носителе. Однако массив данных с приставкой «Биг» настолько велик, что привычными средствами структурирования и аналитики «перелопатить» его невозможно. Поэтому под термином «биг дата» понимают ещё и технологии поиска, обработки и применения неструктурированной информации в больших объемах.

Экскурс в историю и статистику
Словосочетание «большие данные» появилось в 2008 году с легкой руки Клиффорда Линча. В спецвыпуске журнала Nature эксперт назвал взрывной рост потоков информации — big data. В него он отнес любые массивы неоднородных данных свыше 150 Гб в сутки.
Из статистических выкладок аналитических агентств в 2005 году мир оперировал 4-5 эксабайтами информации (4-5 миллиардов гигабайтов), через 5 лет объемы big data выросли до 0,19 зеттабайт (1 ЗБ = 1024 ЭБ). В 2012 году показатели возросли до 1,8 ЗБ, а в 2015 – до 7 ЗБ. Эксперты прогнозируют, что к 2020 году системы больших данных будут оперировать 42-45 зеттабайтов информации.
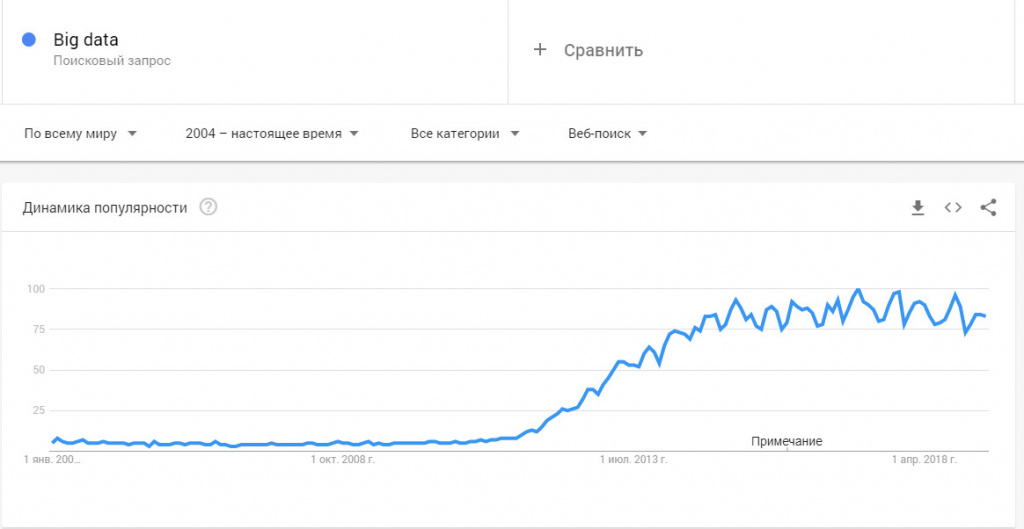
До 2011 года технологии больших данных рассматривались только в качестве научного анализа и практического выхода ни имели. Однако объемы данных росли по экспоненте и проблема огромных массивов неструктурированной и неоднородной информации стала актуальной уже в начале 2012 году. Всплеск интереса к big data хорошо виден в Google Trends.
К развитию нового направления подключились мастодонты цифрового бизнеса – Microsoft, IBM, Oracle, EMC и другие. С 2014 года большие данные изучают в университетах, внедряют в прикладные науки – инженерию, физику, социологию.
Как работает технология big data?
Чтобы массив информации обозначить приставкой «биг» он должен обладать следующими признаками:

Правило VVV:
- Объем (Volume) – данные измеряются по физической величине и занимаемому пространству на цифровом носителе. К «биг» относят массивы свыше 150 Гб в сутки.
- Скорость, обновление (Velocity) – информация регулярно обновляется и для обработки в реальном времени необходимы интеллектуальные технологии больших данных.
- Разнообразие (Variety) – информация в массивах может иметь неоднородные форматы, быть структурированной частично, полностью и скапливаться бессистемно. Например, социальные сети используют большие данные в виде текстов, видео, аудио, финансовых транзакций, картинок и прочего.
В современных системах рассматриваются два дополнительных фактора:
- Изменчивость (Variability) – потоки данных могут иметь пики и спады, сезонности, периодичность. Всплески неструктурированной информации сложны в управлении, требует мощных технологий обработки.
- Значение данных (Value) – информация может иметь разную сложность для восприятия и переработки, что затрудняет работу интеллектуальным системам. Например, массив сообщений из соцсетей – это один уровень данных, а транзакционные операции – другой. Задача машин определить степень важности поступающей информации, чтобы быстро структурировать.
Принцип работы технологии big data основан на максимальном информировании пользователя о каком-либо предмете или явлении. Задача такого ознакомления с данными – помочь взвесить все «за» и «против», чтобы принять верное решение. В интеллектуальных машинах на основе массива информации строится модель будущего, а дальше имитируются различные варианты и отслеживаются результаты.

Современные аналитические агентства запускают миллионы подобных симуляций, когда тестируют идею, предположение или решают проблему. Процесс автоматизирован.
К источникам big data относят:
- интернет – блоги, соцсети, сайты, СМИ и различные форумы;
- корпоративную информацию – архивы, транзакции, базы данных;
- показания считывающих устройств – метеорологические приборы, датчики сотовой связи и другие.
Принципы работы с массивами данных включают три основных фактора:
- Расширяемость системы. Под ней понимают обычно горизонтальную масштабируемость носителей информации. То есть выросли объемы входящих данных – увеличились мощность и количество серверов для их хранения.
- Устойчивость к отказу. Повышать количество цифровых носителей, интеллектуальных машин соразмерно объемам данных можно до бесконечности. Но это не означает, что часть машин не будет выходить из строя, устаревать. Поэтому одним из факторов стабильной работы с большими данными является отказоустойчивость серверов.
- Локализация. Отдельные массивы информации хранятся и обрабатываются в пределах одного выделенного сервера, чтобы экономить время, ресурсы, расходы на передачу данных.
Для чего используют?
Чем больше мы знаем о конкретном предмете или явлении, тем точнее постигаем суть и можем прогнозировать будущее. Снимая и обрабатывая потоки данных с датчиков, интернета, транзакционных операций, компании могут довольно точно предсказать спрос на продукцию, а службы чрезвычайных ситуаций предотвратить техногенные катастрофы. Приведем несколько примеров вне сферы бизнеса и маркетинга, как используются технологии больших данных:
- Здравоохранение. Больше знаний о болезнях, больше вариантов лечения, больше информации о лекарственных препаратах – всё это позволяет бороться с такими болезнями, которые 40-50 лет назад считались неизлечимыми.
- Предупреждение природных и техногенных катастроф. Максимально точный прогноз в этой сфере спасает тысячи жизней людей. Задача интеллектуальных машин собрать и обработать множество показаний датчиков и на их основе помочь людям определить дату и место возможного катаклизма.
- Правоохранительные органы. Большие данные используются для прогнозирования всплеска криминала в разных странах и принятия сдерживающих мер, там, где этого требует ситуация.
Методики анализа и обработки

К основным способам анализа больших массивов информации относят следующие:
- Глубинный анализ, классификация данных. Эти методики пришли из технологий работы с обычной структурированной информацией в небольших массивах. Однако в новых условиях используются усовершенствованные математические алгоритмы, основанные на достижениях в цифровой сфере.
- Краудсорсинг. В основе этой технологии возможность получать и обрабатывать потоки в миллиарды байт из множества источников. Конечное число «поставщиков» не ограничивается ничем. Разве только мощностью системы.
- Сплит-тестирование. Из массива выбираются несколько элементов, которые сравниваются между собой поочередно «до» и «после» изменения. А\В тесты помогают определить, какие факторы оказывают наибольшее влияние на элементы. Например, с помощью сплит-тестирования можно провести огромное количество итераций постепенно приближаясь к достоверному результату.
- Прогнозирование. Аналитики стараются заранее задать системе те или иные параметры и в дальнейшей проверять поведение объекта на основе поступления больших массивов информации.
- Машинное обучение. Искусственный интеллект в перспективе способен поглощать и обрабатывать большие объемы несистематизированных данных, впоследствии используя их для самостоятельного обучения.
- Анализ сетевой активности. Методики big data используются для исследования соцсетей, взаимоотношений между владельцами аккаунтов, групп, сообществами. На основе этого создаются целевые аудитории по интересам, геолокации, возрасту и прочим метрикам.
Большие данные в бизнесе и маркетинге
Стратегии развития бизнеса, маркетинговые мероприятия, реклама основаны на анализе и работе с имеющимися данными. Большие массивы позволяют «перелопатить» гигантские объемы данных и соответственно максимально точно скорректировать направление развития бренда, продукта, услуги.
Например, аукцион RTB в контекстной рекламе работают с big data, что позволяет эффективно рекламировать коммерческие предложения выделенной целевой аудитории, а не всем подряд.
Какие выгоды для бизнеса:
- Создание проектов, которые с высокой вероятностью станут востребованными у пользователей, покупателей.
- Изучение и анализ требований клиентов с существующим сервисом компании. На основе выкладки корректируется работа обслуживающего персонала.
- Выявление лояльности и неудовлетворенности клиентской базы за счет анализа разнообразной информации из блогов, соцсетей и других источников.
- Привлечение и удержание целевой аудитории благодаря аналитической работе с большими массивами информации.
Технологии используют в прогнозировании популярности продуктов, например, с помощью сервиса Google Trends и Яндекс. Вордстат (для России и СНГ).

Методики big data используют все крупные компании – IBM, Google, Facebook и финансовые корпорации – VISA, Master Card, а также министерства разных стран мира. Например, в Германии сократили выдачу пособий по безработице, высчитав, что часть граждан получают их без оснований. Так удалось вернуть в бюджет около 15 млрд. евро.
Недавний скандал с Facebook из-за утечки данных пользователей говорит о том, что объемы неструктурированной информации растут и даже мастодонты цифровой эры не всегда могут обеспечить их полную конфиденциальность.

Например, Master Card используют большие данные для предотвращения мошеннических операций со счетами клиентов. Так удается ежегодно спасти от кражи более 3 млрд. долларов США.
В игровой сфере big data позволяет проанализировать поведение игроков, выявить предпочтения активной аудитории и на основе этого прогнозировать уровень интереса к игре.

Сегодня бизнес знает о своих клиентах больше, чем мы сами знаем о себе – поэтому рекламные кампании Coca-Cola и других корпораций имеют оглушительный успех.
Перспективы развития
В 2019 году важность понимания и главное работы с массивами информации возросла в 4-5 раз по сравнению с началом десятилетия. С массовостью пришла интеграция big data в сферы малого и среднего бизнеса, стартапы:
- Облачные хранилища. Технологии хранения и работы с данными в онлайн-пространстве позволяет решить массу проблем малого и среднего бизнеса: дешевле купить облако, чем содержать дата-центр, персонал может работать удаленно, не нужен офис.
- Глубокое обучение, искусственный интеллект. Аналитические машины имитируют человеческий мозг, то есть используются искусственные нейронные сети. Обучение происходит самостоятельно на основе больших массивов информации.
- Dark Data – сбор и хранение не оцифрованных данных о компании, которые не имеют значимой роли для развития бизнеса, однако они нужны в техническом и законодательном планах.
- Блокчейн. Упрощение интернет-транзакций, снижение затрат на проведение этих операций.
- Системы самообслуживания – с 2016 года внедряются специальные платформы для малого и среднего бизнеса, где можно самостоятельно хранить и систематизировать данные.
Резюме
Мы изучили, что такое big data? Рассмотрели, как работает эта технология, для чего используются массивы информации. Познакомились с принципами и методиками работы с большими данными.
Рекомендуем к прочтению книгу Рика Смолана и Дженнифер Эрвитт «The Human Face of Big Data», а также труд «Introduction to Data Mining» Майкла Стейнбаха, Випин Кумар и Панг-Нинг Тан.
9 методов и технологий анализа big data
Зачем и где применяют. Нейросети обычно используют, если нужно сортировать данные, классифицировать их и на основе входной информации принимать какие-то решения. Обычно нейросети используют для тех задач, с которыми справляется человек: распознать лицо, отсортировать фотографии, определить мошенническую банковскую операцию по ряду признаков. В таких задачах нейросеть заменяет десятки людей и позволяет быстрее принимать решения.
Предиктивная аналитика и big data
Что это. Часто нужно не просто анализировать и классифицировать старые данные, а делать на их основе прогнозы о будущем. Например, по продажам за прошлые 10 лет предположить, какими они будут в следующем году.
В таких прогнозах помогает предиктивная аналитика big data. Слово «предиктивный» образовано от английского «predict» — «предсказывать, прогнозировать», поэтому такую аналитику еще иногда называют прогнозной.
Как это работает. Задача предиктивной аналитики — выделить несколько параметров, которые влияют на данные. Например, мы хотим понять, продолжит ли крупный клиент сотрудничество с компанией.
Для этого изучаем базу прошлых клиентов и смотрим, какие «параметры» клиентов повлияли на их поведение. Это может быть объем покупок, дата последней сделки или даже неочевидные факторы вроде длительности общения с менеджерами. После этого с помощью математических функций или нейросетей строим модель, которая сможет определять вероятность отказа для каждого клиента и предупреждать об этом заранее.
Зачем и где применяют. Предиктивная аналитика нужна везде, где требуется строить прогнозы. Одними из первых ее начали использовать трейдеры, чтобы предсказывать колебания курсов на бирже. Сейчас такую аналитику используют в разных сферах, чтобы предсказывать:
- продажи и поведение клиентов в маркетинге;
- время доставки грузов в логистике;
- мошенничество в банковской и страховой сферах;
- рост компании и финансовые показатели в любых сферах.
На предприятиях и фабриках внедряют платформы индустриального интернета вещей: датчики собирают массивы данных о работе оборудования, а потом системы аналитики, в том числе на основе машинного обучения, обрабатывают их и предсказывают поломки и сроки технического обслуживания. Такие IoT-платформы можно развернуть в облаке: это снижает затраты на разработку, управление и эксплуатацию IoT-сервисов и решений.
Имитационное моделирование
Что это. Иногда возникает ситуация, в которой нужно посмотреть, как поведут себя одни показатели при изменении других. Например, как изменятся продажи, если повысить цену. Ставить такие эксперименты в реальном мире неудобно — это дорого и может привести к серьезным убыткам. Поэтому чтобы не экспериментировать с реальным бизнесом, можно построить имитационную модель.
Как это работает. Представим, что мы хотим посмотреть, как разные факторы влияют на продажи магазина. Для этого берем данные: продажи, цены, количество клиентов и все остальное, имеющее отношение к магазину. На основе этих данных мы строим модель магазина.
Потом вносим в нее изменения — повышаем и понижаем цены, меняем число продавцов, увеличиваем поток посетителей. Все эти изменения влияют на другие показатели — мы можем выбрать самые удачные нововведения и внедрить их в настоящем магазине.
Имитационное моделирование немного похоже на предиктивную аналитику. Только мы предсказываем будущее не по реальным, а по гипотетическим данным.
Имитационную модель можно построить и без big data. Но чем больше данных, тем точнее модель, так как она учитывает больше факторов.
Зачем и где применяют. Везде, где нужно проверять какие-нибудь гипотезы, но тестировать их на реальном бизнесе будет слишком дорого. Например, масштабное изменение цен на долгий срок может обрушить бизнес, так что перед таким шагом лучше провести тест на модели.
Важно помнить, что даже в масштабной модели часто бывают учтены не все факторы. Поэтому моделирование может дать неверный результат, переносить модель в реальность нужно с учетом всех рисков.
Big Data — большая ответственность, большой стресс и деньги | GeekBrains
Подробная информация о Big Data (Большие данные): технологии big data, применение, методы обработки больших данных.
https://d2xzmw6cctk25h.cloudfront.net/post/1959/og_image/069d4ef4f1a6ea909efbb5449d11fb3c.png

Термин Big Data (большие данные) подпорчен современным фантастическим преувеличением новых вещей. Как ИИ поработит людей, а блокчейн построит идеальную экономику — так и большие данные позволят знать абсолютно все про всех и видеть будущее.
Но реальность, как всегда, скучнее и прагматичнее. В больших данных нет никакой магии — как нет ее нигде — просто информации и связей между разными данными становится так много, что обрабатывать и анализировать все старыми способами становится слишком долго.
Появляются новые методы, вместе с ними — новые профессии. Декан факультета Big Data в GeekBrains Сергей Ширкин рассказал, что это за профессии, где они нужны, чем там надо заниматься и что надо уметь. Какие используются методы и технологии обработки больших данных, инструменты и сколько обычно платят специалистам.
Что такое «большие данные»
Вопрос «что называть большими данными» довольно путаный. Даже в публикациях научных журналов описания расходятся. Где-то миллионы наблюдений считаются «обычными» данными, а где-то большими называют уже сотни тысяч, потому что у каждого из наблюдений есть тысяча признаков. Поэтому данные решили условно разбить на три части — малые, средние и большие — по самому простому принципу: объему, который они занимают.
Малые данные — это считанные гигабайты. Средние — все, что около терабайта. Одна из основных характеристик больших данных — вес, который составляет примерно петабайт. Но путаницу это не убрало. Поэтому вот критерий еще проще: все, что не помещается на одном сервере — большие данные.
В малых, средних и больших данных разные принципы работы. Большие данные как правило хранятся в кластере сразу на нескольких серверах. Из-за этого даже простые действия выполняются сложнее.
Например, простая задача — найти среднее значение величины. Если это малые данные, мы просто все складываем и делим на количество. А в больших данных мы не можем собрать сразу всю информацию со всех серверов. Это сложно. Зачастую надо не данные тянуть к себе, а отправлять отдельную программу на каждый сервер. После работы этих программ образуются промежуточные результаты, и среднее значение определяется по ним.

Сергей Ширкин
Какие компании занимаются большими данными
Первыми с большими данными, либо с «биг дата», начали работать сотовые операторы и поисковые системы. У поисковиков становилось все больше и больше запросов, а текст тяжелее, чем цифры. На работу с абзацем текста уходит больше времени, чем с финансовой транзакцией. Пользователь ждет, что поисковик отработает запрос за долю секунды — недопустимо, чтобы он работал даже полминуты. Поэтому поисковики первые начали работать с распараллеливанием при работе с данными.
Чуть позже подключились различные финансовые организации и ритейл. Сами транзакции у них не такие объемные, но большие данные появляются за счет того, что транзакций очень много.
Количество данных растет вообще у всех. Например, у банков и раньше было много данных, но для них не всегда требовались принципы работы, как с большими. Затем банки стали больше работать с данными клиентов. Стали придумывать более гибкие вклады, кредиты, разные тарифы, стали плотнее анализировать транзакции. Для этого уже требовались быстрые способы работы.
Сейчас банки хотят анализировать не только внутреннюю информацию, но и стороннюю. Они хотят получать большие данные от того же ритейла, хотят знать, на что человек тратит деньги. На основе этой информации они пытаются делать коммерческие предложения.
Сейчас вся информация связывается между собой. Ритейлу, банкам, операторам связи и даже поисковикам — всем теперь интересны данные друг друга.
Каким должен быть специалист по большим данным
Поскольку данные расположены на кластере серверов, для их обработки используется более сложная инфраструктура. Это оказывает большую нагрузку на человека, который с ней работает — система должна быть очень надежной.
Сделать надежным один сервер легко. Но когда их несколько — вероятность падения возрастает пропорционально количеству, и так же растет и ответственность дата-инженера, который с этими данными работает.
Аналитик big data должен понимать, что он всегда может получить неполные или даже неправильные данные. Он написал программу, доверился ее результатам, а потом узнал, что из-за падения одного сервера из тысячи часть данных была отключена, и все выводы неверны.
Взять, к примеру, текстовый поиск. Допустим все слова расположены в алфавитном порядке на нескольких серверах (если говорить очень просто и условно). И вот отключился один из них, пропали все слова на букву «К». Поиск перестал выдавать слово «Кино». Следом пропадают все киноновости, и аналитик делает ложный вывод, что людей больше не интересуют кинотеатры.
Поэтому специалист по большим данным должен знать принципы работы от самых нижних уровней — серверов, экосистем, планировщиков задач — до самых верхнеуровневых программ — библиотек машинного обучения, статистического анализа и прочего. Он должен понимать принципы работы железа, компьютерного оборудования и всего, что настроено поверх него.
В остальном нужно знать все то же, что и при работе с малыми данным. Нужна математика, нужно уметь программировать и особенно хорошо знать алгоритмы распределенных вычислений, уметь приложить их к обычным принципам работы с данными и машинного обучения.
Какие используются инструменты и технологии big data
Поскольку данные хранятся на кластере, для работы с ними нужна особая инфраструктура. Самая популярная экосистема — это Hadoop. В ней может работать очень много разных систем: специальных библиотек, планировщиков, инструментов для машинного обучения и многого другое. Но в первую очередь эта система нужна, чтобы анализировать большие объемы данных за счет распределенных вычислений.
Например, мы ищем самый популярный твит среди данных разбитых на тысяче серверов. На одном сервере мы бы просто сделали таблицу и все. Здесь мы можем притащить все данные к себе и пересчитать. Но это не правильно, потому что очень долго.
Поэтому есть Hadoop с парадигмами Map Reduce и фреймворком Spark. Вместо того, чтобы тянуть данные к себе, они отправляют к этим данным участки программы. Работа идет параллельно, в тысячу потоков. Потом получается выборка из тысячи серверов на основе которой можно выбрать самый популярный твит.
Map Reduce более старая парадигма, Spark — новее. С его помощью достают данные из кластеров, и в нем же строят модели машинного обучения.
Какие профессии есть в сфере больших данных
Две основные профессии — это аналитики и дата-инженеры.
Аналитик прежде всего работает с информацией. Его интересуют табличные данные, он занимается моделями. В его обязанности входит агрегация, очистка, дополнение и визуализация данных. То есть, аналитик в биг дата — это связующее звено между информацией в сыром виде и бизнесом.
У аналитика есть два основных направления работы. Первое — он может преобразовывать полученную информацию, делать выводы и представлять ее в понятном виде.
Второе — аналитики разрабатывают приложения, которые будет работать и выдавать результат автоматически. Например, делать прогноз по рынку ценных бумаг каждый день.
Дата инженер — это более низкоуровневая специальность. Это человек, который должен обеспечить хранение, обработку и доставку информации аналитику. Но там, где идет поставка и очистка — их обязанности могут пересекаться
Bigdata-инженеру достается вся черная работа. Если отказали системы, или из кластера пропал один из серверов — подключается он. Это очень ответственная и стрессовая работа. Система может отключиться и в выходные, и в нерабочее время, и инженер должен оперативно предпринять меры.
Это две основные профессии, но есть и другие. Они появляются, когда к задачам, связанным с искусственным интеллектом, добавляются алгоритмы параллельных вычислений. Например, NLP-инженер. Это программист, который занимается обработкой естественного языка, особенно в случаях, когда надо не просто найти слова, а уловить смысл текста. Такие инженеры пишут программы для чат-ботов и диалоговых систем, голосовых помощников и автоматизированных колл-центров.
Есть ситуации, когда надо проклассифицировать миллиарды картинок, сделать модерацию, отсеять лишнее и найти похожее. Эти профессии больше пересекаются с компьютерным зрением.
Сколько времени занимает обучение
У нас обучение идет полтора года. Они разбиты на шесть четвертей. В одних идет упор на программирование, в других — на работу с базами данных, в третьих — на математику.
В отличии, например, от факультета ИИ, здесь поменьше математики. Нет такого сильного упора на математический анализ и линейную алгебру. Знания алгоритмов распределенных вычислений нужны больше, чем принципы матанализа.
Но полтора года достаточно для реальной работы с обработкой больших данных только если у человека был опыт работы с обычными данными и вообще в ИТ. Остальным студентам после окончания факультета рекомендуется поработать с малыми и средними данными. Только после этого специалиста могут допустить к работе с большими. После обучения стоит поработать дата-саентистом — поприменять машинное обучение на разных объемах данных.
Когда человек устраивается в большую компанию — даже если у него был опыт — чаще всего его не допустят до больших объемов данных сразу, потому что цена ошибки там намного выше. Ошибки в алгоритмах могут обнаружиться не сразу, и это приведет к большим потерям.
Какая зарплата считается адекватной для специалистов по большим данным
Сейчас есть очень большой кадровый голод среди дата-инженеров. Работа сложная, на человека ложится много ответственности, много стресса. Поэтому специалист со средним опытом получает около двухсот тысяч. Джуниор — от ста до двухсот.
У аналитика данных стартовая зарплата может быть чуть меньше. Но там нет работы сверх рабочего времени, и ему не будут звонить в нерабочее время из-за экстренных случаев.
Как готовиться к собеседованиям
Не нужно углубляться только в один предмет. На собеседованиях задают вопросы по статистике, по машинному обучению, программированию. Могут спросить про структуры больших данных, алгоритмы, применение, технологии, про кейсы из реальной жизни: упали сервера, случилась авария — как устранять? Могут быть вопросы по предметной сфере — то, что ближе к бизнесу
И если человек слишком углубился в одну математику, и на собеседовании не сделал простое задание по программированию, то шансы на трудоустройство снижаются. Лучше иметь средний уровень по каждому направлению, чем показать себя хорошо в одном, а в другом провалиться полностью.
Есть список вопросов, которые задают на 80 процентах собеседований. Если это машинное обучение — обязательно спросят про градиентный спуск. Если статистика — нужно будет рассказать про корреляцию и проверку гипотез. По программированию скорее всего дадут небольшую задачу средней сложности. А на задачах можно легко набить руку — просто побольше их решать.
Где набираться опыта самостоятельно
Python можно подтянуть на Питонтьютор, работы с базой данных — на SQL-EX. Там даются задачи, по которым на практике учатся делать запросы.
Высшая математика — Mathprofi. Там можно получить понятную информацию по математическому анализу, статистике и линейной алгебре. А если плохо со школьной программой, то есть сайт youclever.org
Распределенные же вычисления тренировать получится только на практике. Во-первых для этого нужна инфраструктура, во-вторых алгоритмы могут быстро устаревать. Сейчас постоянно появляется что-то новое.
Какие тренды обсуждает сообщество
Постепенно набирает силу еще одно направление, которое может привести к бурному росту количества данных — Интернет вещей (IoT). Большие данные такого рода поступают с датчиков устройств, объединенных в сеть, причем количество датчиков в начале следующего десятилетия должно достигнуть десятков миллиардов.
Устройства самые разные — от бытовых приборов до транспортных средств и промышленных станков, непрерывный поток информации от которых потребует дополнительной инфраструктуры и большого числа высококвалифицированных специалистов. Это означает, что в ближайшее время возникнет острый дефицит дата инженеров и аналитиков больших данных.
Учебное пособие по
Big Data Hadoop для начинающих: научитесь за 7 дней!
![]()
- Home
Тестирование
- Back
- Agile Testing
- BugZilla
- Cucumber
- Тестирование базы данных
- ETL Testing
- Jmeter Backing
- Jmeter Testing
- Jmeter
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
Jmeter
- Назад
- Центр качества (ALM)
- RPA
- SAP Testing
- Management Test
0004
SAP
- Назад
- ABAP
- APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- FICO
- HANA
Web
- Angular
- ASP.Net
- C
- C #
- C ++
- CodeIgniter
- СУБД
- JavaScript
- Назад
- Java
- JSP
- Kotlin
- Linux
- Linux
- Kotlin
- Linux
- Perl
Web
js
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
000
0004 SQL
Обязательно учите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Business Analyst
- Веб-сайт сборки
- CCNA
- Облачные вычисления
- COBOL 9000 Compiler
- 0005
- Ethical Hacking
- Учебные пособия по Excel
- Программирование на Go
- IoT
- ITIL
- Jenkins
- MIS
- Сетевые подключения
- Операционная система
- Назад
- 9000 Встроенный COBOL 9000 Дизайн 9000
Управление проектами Обзоры
- Salesforce
- SEO
- Разработка программного обеспечения
- VB A
- 0005
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Хранилище данных
0005
HBOps
HBOps
.
Страница не найдена
![]()
ONLINESTUDIES
На базе Keystone
Войти
Регистр
В сети
Мастер
кандидат наук
.
приложений для работы с большими данными в реальном времени в различных областях
Big Data за последние несколько лет сыграл важную роль в изменении правил игры для большинства отраслей. Согласно Wikibon, доходы мирового рынка больших данных для программного обеспечения и услуг, по прогнозам, вырастут с 42 млрд долларов в 2018 году до 103 млрд долларов в 2027 году, при этом среднегодовой темп роста (CAGR) составит 10,48%. Вот почему сертификация Big Data является одним из самых сложных навыков в отрасли.В этом блоге о приложениях для больших данных я расскажу вам о различных отраслях, где я расскажу, как большие данные меняют их.
Приложения для больших данных
Основная цель приложений для больших данных — помочь компаниям принимать более информативные бизнес-решения путем анализа больших объемов данных. Он может включать журналы веб-сервера, данные о потоках кликов в Интернете, контент и отчеты об активности в социальных сетях, текст из электронных писем клиентов, сведения о звонках по мобильному телефону и данные о машинах, полученные с помощью нескольких датчиков.
Организации из разных сфер вкладывают средства в приложения для больших данных для изучения больших наборов данных с целью выявления всех скрытых закономерностей, неизвестных корреляций, рыночных тенденций, предпочтений клиентов и другой полезной бизнес-информации. В этом блоге мы рассмотрим:
Давайте разберемся, как приложения больших данных играют важную роль в различных областях.
Приложения для больших данных: Здравоохранение
Уровень данных, генерируемых в системах здравоохранения, нетривиален.Традиционно отрасль здравоохранения отставала в использовании больших данных из-за ограниченной способности стандартизировать и консолидировать данные.
Но теперь аналитика больших данных улучшила здравоохранение за счет предоставления персонализированной медицины и предписывающей аналитики. Исследователи собирают данные, чтобы увидеть, какие методы лечения более эффективны при определенных состояниях, выявить закономерности, связанные с побочными эффектами лекарств, и получить другую важную информацию, которая может помочь пациентам и сократить расходы.
С расширением внедрения мобильных технологий, электронного здравоохранения и носимых устройств объем данных растет с экспоненциальной скоростью.Сюда входят данные электронных медицинских карт, данные изображений, данные пациентов, данные датчиков и другие формы данных.
Сопоставляя медицинские данные с наборами географических данных, можно предсказать болезнь, которая разовьется в определенных областях. На основе прогнозов легче разработать стратегию диагностики и спланировать запасы сывороток и вакцин.
Приложения для больших данных: производство
Производство с прогнозированием обеспечивает практически нулевое время простоя и прозрачность.Для систематического преобразования данных в полезную информацию требуется огромное количество данных и расширенные инструменты прогнозирования.
Основные преимущества использования приложений больших данных в обрабатывающей промышленности:
- Отслеживание качества продукции и дефектов
- Планирование поставок
- Отслеживание дефектов производственного процесса
- Прогнозирование выпуска
- Повышение энергоэффективности
- Тестирование и моделирование новых производственных процессов
- Поддержка массовой настройки производства

Приложения для больших данных: СМИ и развлечения
Различные компании в сфере средств массовой информации и индустрии развлечений сталкиваются с новыми бизнес-моделями в том, как они создают, продают и распространять их контент.Это происходит из-за того, что текущий потребитель ищет и требует доступа к контенту в любом месте, в любое время и с любого устройства.
Big Data предоставляет действенные точки информации о миллионах людей. Теперь издательские среды адаптируют рекламу и контент к потребителям. Эти идеи собираются с помощью различных действий по интеллектуальному анализу данных. Приложения для больших данных приносят пользу индустрии медиа и развлечений:
- Предсказание того, чего хочет аудитория
- Оптимизация расписания
- Увеличение количества привлеченных и удерживаемых клиентов
- Таргетинг рекламы
- Монетизация контента и разработка новых продуктов

Большой Приложения данных: Интернет вещей (IoT)
Данные, извлеченные из устройств IoT , обеспечивают отображение взаимосвязей между устройствами.Такие сопоставления использовались различными компаниями и правительствами для повышения эффективности. Интернет вещей также все чаще используется как средство сбора сенсорных данных, и эти сенсорные данные используются в медицине и на производстве.

Приложения для больших данных: Правительство
Использование и внедрение больших данных в государственные процессы позволяет добиться повышения эффективности с точки зрения затрат, производительности и инноваций. В государственных учреждениях одни и те же наборы данных часто применяются в нескольких приложениях, и это требует совместной работы нескольких отделов.
Поскольку правительство в основном действует во всех сферах, оно играет важную роль в создании инновационных приложений для больших данных во всех без исключения доменах. Позвольте мне обратиться к некоторым из основных областей:
Кибербезопасность и разведка
Федеральное правительство запустило план исследований и разработок в области кибербезопасности, который полагается на способность анализировать большие наборы данных с целью повышения безопасности компьютерных сетей США. .
Национальное агентство геопространственной разведки создает «Карту мира», которая может собирать и анализировать данные из самых разных источников, таких как спутниковые данные и данные социальных сетей.Он содержит различные данные из секретных, несекретных и сверхсекретных сетей.
Прогнозирование и предотвращение преступности
Полицейские департаменты могут использовать расширенную аналитику в реальном времени для предоставления действенной информации, которую можно использовать для понимания преступного поведения, выявления моделей преступлений / инцидентов и обнаружения угроз на основе местоположения.
Оценка фармацевтических препаратов
Согласно отчету McKinsey, технологии больших данных могут снизить затраты на исследования и разработки для фармацевтических производителей на 40–70 миллиардов долларов.FDA и NIH используют технологии больших данных для доступа к большим объемам данных для оценки лекарств и лечения.
Научные исследования
Национальный научный фонд инициировал долгосрочный план:
- Внедрение новых методов извлечения знаний из данных
- Разработка новых подходов к образованию
- Создание новой инфраструктуры для «управления, курирования» , и предоставлять данные сообществам ».
Прогноз погоды
NOAA (Национальное управление океанических и атмосферных исследований) каждую минуту собирает данные с наземных, морских и космических датчиков.Daily NOAA использует большие данные для анализа и извлечения ценности из более чем 20 терабайт данных.
Tax Compliance
Приложения для больших данных могут использоваться налоговыми организациями для анализа как неструктурированных, так и структурированных данных из различных источников с целью выявления подозрительного поведения и множественных идентификационных данных. Это поможет в выявлении налогового мошенничества.
Оптимизация трафика
Большие данные помогают в агрегировании данных о трафике в реальном времени, собранных с датчиков дороги, устройств GPS и видеокамер.Потенциальные проблемы с дорожным движением в густонаселенных районах можно предотвратить, изменив маршруты общественного транспорта в режиме реального времени.

Я только что привел некоторые из ярких примеров приложений больших данных, но существует бесчисленное множество способов, которыми большие данные революционизируют каждую область. Надеюсь, вы нашли этот блог достаточно информативным. В своем следующем блоге я расскажу о карьерных возможностях в больших данных и Hadoop.
Теперь, когда вы знакомы с различными сертификатами Hadoop, ознакомьтесь с учебным курсом Hadoop от Edureka, надежной компании по онлайн-обучению, в сети которой насчитывается более 250 000 довольных учащихся по всему миру.Учебный курс по сертификации Big Data Hadoop от Edureka помогает учащимся стать экспертами в области HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume и Sqoop, используя примеры использования в реальном времени в области розничной торговли, социальных сетей, авиации, туризма, финансов.
Есть к нам вопрос? Пожалуйста, отметьте это в разделе комментариев, и мы свяжемся с вами.
.
Что такое большие данные? | Определение больших данных | V больших данных
Нет места, где бы не существовали большие данные! Интерес к тому, что такое большие данные, резко возрос в последние несколько лет. Позвольте мне рассказать вам несколько ошеломляющих фактов! Forbes сообщает, что каждую минуту пользователи просматривают 4,15 миллиона видео на YouTube , отправляют 456000 твитов, в Twitter, публикуют 46 740 фотографий в Instagram и 510 000 комментариев, опубликовано и 293 000 статусов обновлено в Facebook!
Только представьте себе, какой огромный объем данных создается в результате таких действий.Это постоянное создание данных с использованием социальных сетей, бизнес-приложений, телекоммуникаций и различных других областей ведет к формированию больших данных.
Чтобы объяснить , что такое большие данные , я расскажу о следующих темах:
- Эволюция больших данных
- Определение больших данных
- Характеристики больших данных
- Аналитика больших данных
- Промышленные приложения больших данных Данные
- Объем больших данных
Эволюция больших данных
Прежде чем продолжить изучение, позвольте мне начать с понимания того, почему эта технология приобрела такое большое значение.
Когда вы, ребята, в последний раз использовали дискету или компакт-диск для хранения данных? Дай угадаю, пришлось вернуться в начало 21 века, верно? Использование ручных бумажных записей, файлов, дискет и дисков теперь устарело. Причина этого — экспоненциальный рост данных. Люди начали хранить свои данные в системах реляционных баз данных, но с жаждой новых изобретений, технологий, приложений с быстрым временем отклика и с появлением Интернета даже этого сейчас недостаточно.Это поколение непрерывных и массивных данных можно назвать большими данными. Есть еще несколько факторов, характеризующих большие данные, которые я объясню позже в этом блоге.
Forbes сообщает, что каждый день создается 2,5 квинтиллиона байтов данных в наших текущих темпах, но этот темп только ускоряется. Интернет вещей (IoT) — одна из таких технологий, которая играет важную роль в этом ускорении. 90% всех сегодняшних данных было создано за последние два года.
Определение больших данных
Что такое большие данные | Аналитика больших данных | Edureka
Это видео дает вам краткое введение в большие данные.Вы также познакомитесь с практическими примерами его использования, чтобы понять, насколько он может быть полезен.
Что такое большие данные?
Итак, прежде чем я объясню, что такое большие данные, позвольте мне также рассказать вам, чем они не являются! Наиболее распространенный миф, связанный с этим, заключается в том, что речь идет только о размере или объеме данных. Но на самом деле дело не только в собираемых «больших» объемах данных. Большие данные относится к большим объемам данных, которые поступают из различных источников и имеют разные форматы.Даже раньше в базах данных хранились огромные данные, но из-за разнообразия этих данных традиционные системы реляционных баз данных неспособны обрабатывать эти данные. Большие данные — это гораздо больше, чем набор наборов данных в различных форматах, это важный актив, который можно использовать для получения бесчисленных преимуществ.
Три различных формата больших данных:
- Структурированные: Организованный формат данных с фиксированной схемой.Пример: РСУБД
- Полуструктурированные: Частично организованные данные, не имеющие фиксированного формата. Пример: XML, JSON
- Неструктурированные: Неорганизованные данные с неизвестной схемой. Пример: аудио, видео файлы и т. Д.
Характеристики больших данных
Ниже приведены характеристики:
На приведенном выше изображении показаны пять V больших данных, но по мере того, как данные продолжают развиваться, будут В.Я перечисляю еще пять V, которые постепенно развивались с течением времени:
- Действительность: правильность данных
- Изменчивость: динамическое поведение
- Волатильность: тенденция к изменению во времени
- Уязвимость: уязвимость для взлома или атак
- Визуализация: визуализация осмысленное использование данных
Аналитика больших данных
Теперь, когда я рассказал вам, что такое большие данные и как они генерируются в геометрической прогрессии, позвольте мне представить вам очень интересный пример того, как Starbucks , один из ведущих сеть кофеен использует эти большие данные.
Я наткнулся на эту статью Forbes, в которой сообщалось, как Starbucks использовала эту технологию для анализа предпочтений своих клиентов, чтобы улучшить и персонализировать их опыт. Они проанализировали привычки своих членов к покупке кофе, а также их предпочтительные напитки и то, в какое время дня они обычно заказывают. Таким образом, даже когда люди посещают «новое» заведение Starbucks, система точек продаж этого магазина может идентифицировать покупателя с помощью его смартфона и отдавать бариста предпочтительный заказ.Кроме того, в зависимости от предпочтений при заказе их приложение будет предлагать новые продукты, которые могут быть заинтересованы в опробовании клиентов. Друзья мои, это то, что мы называем аналитикой больших данных.
В основном, он в основном используется компаниями для облегчения своего роста и развития. Это в основном включает в себя применение различных алгоритмов интеллектуального анализа данных к заданному набору данных, которые затем помогут им в принятии более эффективных решений.
Существует несколько инструментов для обработки больших данных, таких как Hadoop , Pig , Hive , Cassandra , Spark , Kafka и т. Д.в зависимости от требований организации.

Большие данные Приложения
Вот некоторые из следующих областей, где произошла революция в Приложениях больших данных :
- Развлечения: Netflix и Amazon используют его для создания шоу и фильмов рекомендации своим пользователям.
- Страхование: Использует эту технологию для прогнозирования заболеваний, несчастных случаев и определения цены на свою продукцию.
- Без водителя Автомобили: Автомобили Google без водителя собирают около одного гигабайта данных в секунду. Эти эксперименты требуют все больше и больше данных для их успешного выполнения.
- Образование: Выбор технологий на основе больших данных в качестве инструмента обучения вместо традиционных методов лекций, которые улучшили обучение студентов, а также помогли учителю лучше отслеживать их успеваемость.
- Автомобиль: Компания Rolls Royce применила эту технологию, установив в свои двигатели и силовые установки сотни датчиков, которые регистрируют каждую мельчайшую деталь их работы.Об изменениях данных в режиме реального времени сообщается инженерам, которые решат, как лучше всего действовать, например, составить график технического обслуживания или направить группы инженеров, если этого потребует проблема.
- Правительство: Очень интересный пример использования в области политики для анализа моделей и влияния на результаты выборов. Cambridge Analytica Ltd. — одна из таких организаций, которая полностью использует данные для изменения поведения аудитории и играет важную роль в избирательном процессе.
Объем больших данных
- Многочисленные вакансии: Карьерные возможности, относящиеся к области больших данных, включают: аналитика больших данных, инженера по большим данным, архитектора решений для больших данных и т. Д. По данным IBM, 59% всего спроса на работу в области Data Science and Analytics (DSA) приходится на финансы и страхование, профессиональные услуги и ИТ.
- Растущий спрос на Analytics Professional: Статья Forbes показывает, что «IBM прогнозирует, что спрос на специалистов по анализу данных вырастет на 28%».К 2020 году количество рабочих мест для всех специалистов по обработке данных в США увеличится на 364 000 вакансий до 2 720 000, согласно данным IBM.
- Аспекты заработной платы: Forbes сообщил, что работодатели готовы платить премию в размере 8736 долларов сверх средней заработной платы бакалавров и выпускников, при этом успешные кандидаты получают стартовую зарплату в размере 80 265 долларов
- Принятие аналитики больших данных: Огромный рост использование анализа больших данных во всем мире.

На изображении выше изображен растущий рыночный доход от больших данных в миллиардах единиц.Долларов с 2011 по 2027 год. Так что все это было в блоге, и я надеюсь, что это было полезно.
Есть к нам вопрос? Пожалуйста, отметьте это в разделе комментариев, и мы свяжемся с вами.
.